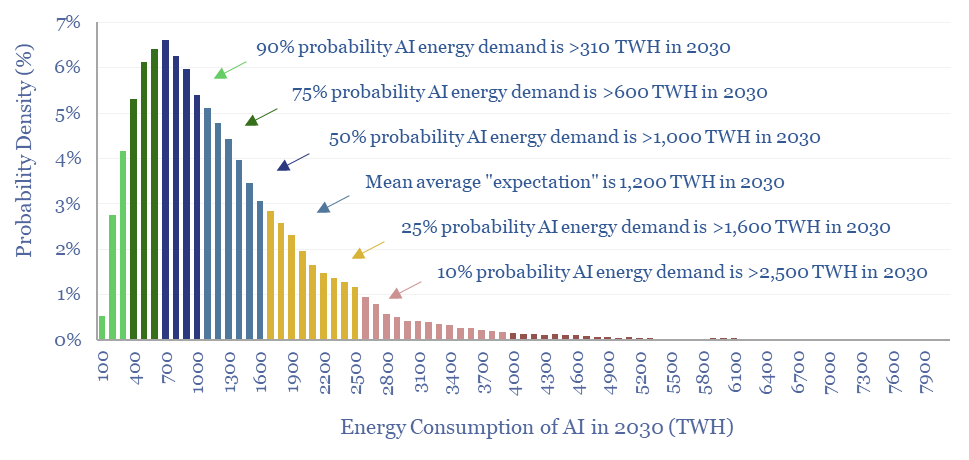
Rising energy demands of AI are now the biggest uncertainty in all of global energy. To understand why, this 17-page note gives an overview of AI computing from first principles, across transistors, DRAM, GPUs and deep learning. GPU efficiency will inevitably increase, but compute increases faster. AI most likely uses 300-2,500 TWH in 2030, with a base case of 1,000 TWH.
The energy demands of AI are the fastest growing component of total global energy demand, which will transform the trajectory of gas and power and even regulated gas pipelines, as recapped on pages 2-3.
These numbers are so material that they deserve some deeper consideration. Hence this 17-page note is an overview of AI computation.
Of course, in 17-pages, we can only really scratch the surface, but we do think the report illustrates why computing efficiency will improve by 2-50x by 2030, and total compute will increase 3-5x faster. Thus a range of forecasts is more sensible than a single point estimate.
Transistors made of semiconductor materials, underpin all modern computing by allowing one circuit to control another. The basic working principles of MOSFETs are explained briefly on page 4.
All computers also contain a clock which is an oscillator circuit, generating pulses at a precise frequency. A faster clock accelerates computing, but also amplifies switching losses in transistors, per page 5.
Combinations of transistors can enact logical and arithmetic functions, from simple AND, OR and NAND gates, to matrix multiplications in the tensor cores of GPUs, as shown on page 6.
Transistors and capacitors can be arranged into DRAM cells, the basis of fast-acting computer memory. But DRAM also has a continued energy draw to refresh leakage currents, as quantified on page 7.
GPUs are fundamentally different from CPUs, as they carve up workloads into thousands (sometimes millions) of parallel processing threads, implemented by built-in cores, each integrated with nearby DRAM, and as illustatrated for NVIDIA’s A100 GPU on page 8.
An AI model is just a GPU simulating a neural network. Hence we outline a simple, understandable neural network, training via back-propagation of errors, and the model’s inherent ‘generativity’ on pages 9-10.
A key challenge for energy analysts is bridging between theoretical peak performance at the GPU level and actual performance of AI computing systems. The gap is wide. The shortfall is quantified on page 11.
Our favorite analogy for explaining the shortfall is via the energy consumption of planes, which can in principle reach 80 passenger miles per gallon. Jet engines provide a lot of thrust. But you also need to get the plane into the air (like pulling information from memory), keep it in the air (refreshing data in DRAM) and fuel consumption per passenger falls off a cliff if there are very few passengers (memory bandwidth constraints, underutilization of GFLOPS). See page 12.
If you understand the analogies above, then it is going to be trivial to improve the energy consumption of AI, simply by building larger and more actively used neural network models that crunch more data, and utilize more of the chronically underutilized compute power in GPUs. Other avenues to improve GPU efficiency are on page 13.
The energy consumption of AI is strongly reminiscent of the Jevons effect. Increasing the energy efficiency of GPUs goes hand in hand with increasing the total compute of these models, which will itself rise 3-5x faster, as evidenced by data and case studies on pages 14-15.
Forecasting the future energy demands of AI therefore involves several exponentially increasing variables, which are all inherently uncertain, and then multiplying these numbers together. This produces a wide confidence interval of possible outcomes, around our base case forecast of 1,000 TWH pa. Implications are on pages 16-17.
This note may also be read alongside our overview of the gas and power market implication of AI, as shown below.